project overview
Project Summary (pdf 68kB)
NSF ITR Meeting Poster, June 2004
(pdf 85kB)
The fundamental goal of this research is to develop a broadly useable framework for pattern analysis and classification of animal vocalizations, by integrating successful models and ideas from the field of speech processing and recognition into bioacoustics.
Project Goals
General Approach
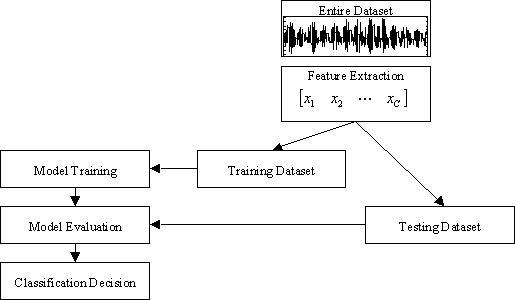
The basic idea behind our approach is the automatic classification of animal vocalizations. The vocalizations can be classified using various criteria including vocalization type, the individual making the vocalization, behavior of the animal during the vocalization, or by various physiological indicators such as stress or estrous cycle. The general layout of a typical automatic classification system is shown below.
First, each vocalization in the dataset is converted from a waveform to a set of features. These features quantify the vocalization in many fewer values than it would take to represent the vocalization as a sampled waveform. The dataset is then broken into a training set and a testing set. The training set is used to train the vocalization models. One model is trained for each type of vocalization. Once the models are trained, the simularity between each model and a testing set vocalization is evaluated. The model which best fits the test vocalization is chosen to be the correct model and the vocalization is labeled appropriately.
Primary Project Components
Marquette University / Speech and Signal Processing Laboratory