
Figure 1. Norwegian ortolan bunting
HMM-based song-type classification and individual identification of ortolan bunting (Emberiza Hortulana L)
Kuntoro Adi and Marek Trawicki
This research presents a method for automatic song-type classification and individual identification of ortolan bunting (Emberiza Hortulana L). This method is based on Hidden Markov Models (HMMs) commonly used in the signal processing and automatic speech recognition research communities. The features used for classification and identification include both fundamental frequency and spectral characteristics. Spectral features are derived from frequency-weighted cepstral coefficients. Using these features one HMM is trained for each type of vocalization both for individual bird and across the entire population. Preliminary results indicate accuracies of above 90% for both song-type classification and individual identification tasks.
Introduction
Many bird studies require identification of bird vocalization. Most of these studies based on manual inspection and labeling of sound spectrographs. They sometimes involve a large corpus that are extremely labor extensive. Manual inspection of multiple vocalization sometimes prone to error.
Automated classification based on well defined acoustic features would improve the quality of measurements. Recent progress in automated speech recognition encourages to achieve a reliable automated recognition for bird vocalizations.
Objective
This research describes method for automatic song-type classification and individual identification of the ortolan bunting (Emberiza Hortulana L). The method is based on Hidden Markov Models (HMMs) commonly used in the signal processing and automatic speech recognition research community.
Song analysis
The subjects for this study are ortolan bunting bird (Tomasz S. Osiejuk, 2003). The ortolan bunting Emberiza hortulana is an age-limited bird that has a relatively simple song and small repertoire size (typically 2-3 song types). Songs of ortolan buntings are described in terms of their syllable, song-type and song variant. In total, there are 63 different song types and 234 different song variants, composed of 20 different syllables.
Figure 1. Norwegian ortolan bunting
a. Syllable
A syllable is a minimal unit of song production. A song is described by using letter notation, e.g. aaaabb or hhhhuff, where letters denote particular syllables. Syllables of the same category have the same shape on sonograms, but they might differ in length and frequency between individuals

Figure 2. Syllable types of ortolan bunting (Osiejuk, 2003)
b. Song-type
Song-type indicates a group of songs that consists of the same syllables arranged in the same order.
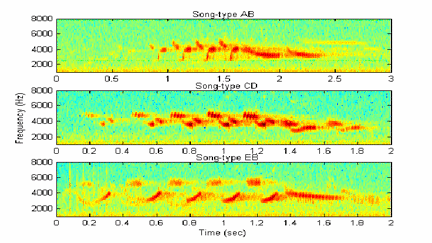
Figure 3. Song-type AB, CD and EB
c. Song-variant
Song-variants are songs of the same type, with differ only in the number of syllables within the songs. As an example: song-type gb has song variants: gggb, ggbbbb, gggbb The initial and final syllables may slightly differ in amplitude and frequency, probably because of sound production mechanisms.
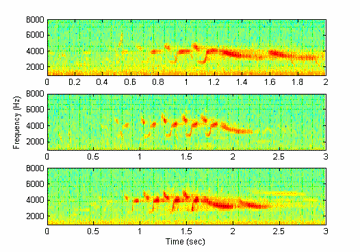
Figure 4. Song-variant AB: aaabb, aaaaab, aaaabb
HMM-based song-type classification and individual identification
a. HMM for song-type classification
Hidden Markov Models
Markov Property
b. HMM Scheme
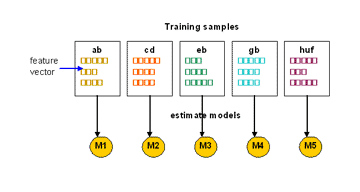
Figure 5. HMM models for song-types
First, an HMM is trained for each song-type using a number of examples of that song. In this case the song-type examples consist of song-type ab, cd, eb, gb and huf. To recognize some unknown song, the likelihood of each model generating that song-type is calculated; and the most likely model identifies the song-type.
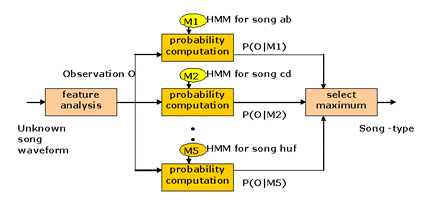
Figure 6. Block diagram of song-type recognizer
c. Results
Song-type classification
The song-type classification experiment is similar to speech recognition experiment on human speech. Five different common ortolan bunting song-types are classified, namely, ab, cd, eb, gb, and huf.
| No | Features | Accuracy (%) |
1 2 3 4 5 6 7 |
Pitch Cepstral coefficient (MFCC) MFCC + pitch MFCC + pitch + relative pitch MFCC + pitch + relative pitch + energy MFCC_E_D_A (MFCC + energy + delta + delta-delta) MFCC_E_D_A with cepstral variance normalization |
71.20 93.60 92.00 92.00 94.40 92.10 96.90 |
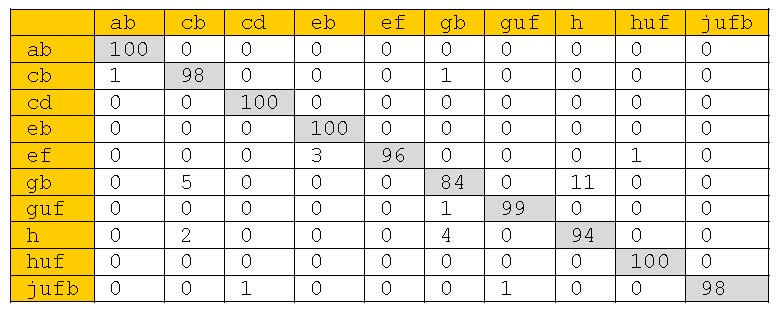
Figure 7. Confusion Matrix of 10 Commonly Sung Song-Types
Individual identification
| No | Features | Accuracy (%) |
1 2 3 4 |
MFCC MFCC_O MFCC_O_D MFCC_O_D_A |
94.00 93.33 93.33 94.00 |
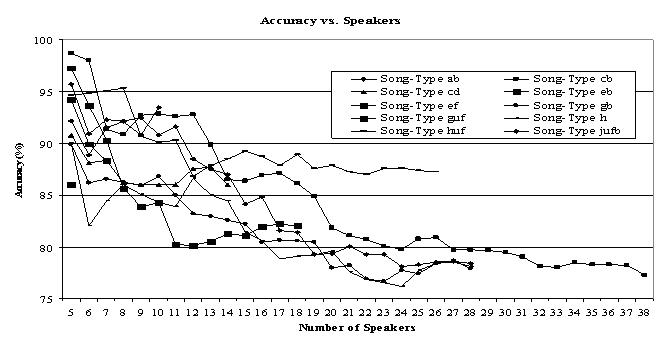
Figure 8. Speaker Identification (Song-Type Dependent)
Discussion
HMMs have been successfully applied to modeling sequences of spectra in song-type recognition systems and individual identification. HMMs can model sequence of discrete symbol and sequence vectors. However, we can not apply both the discrete and continuous HMMs to observation which consists of continuous values and discrete symbols. The alternative use of multi-space probability distribution HMM to handle the unvoiced regions of the vocalization
Future work